-
Email
[email protected] -
Phone
+32 472 31 34 79 -
BirthDate
-
Location
3920 Lommel, Belgium
Placement Prediction using Machine Learning
2025/02 - 2025/03
Introduction
This project explored the use of machine learning techniques to predict whether a student would be placed in a job based on academic and background factors. Our aim was to extract meaningful insights from the dataset and build a predictive model to support career services in identifying placement likelihood. The project was split between two team members: I focused on placement prediction and data analysis, while my teammate worked on salary prediction.
Technologies Used
- Python for data preprocessing, analysis, and model training
- Pandas and Matplotlib for data cleaning and visualization
- Scikit-learn for model development and evaluation
- Jupyter Notebooks for experimentation and presentation
- Logistic Regression, Decision Trees, and Random Forest as predictive models
My Role & Contributions
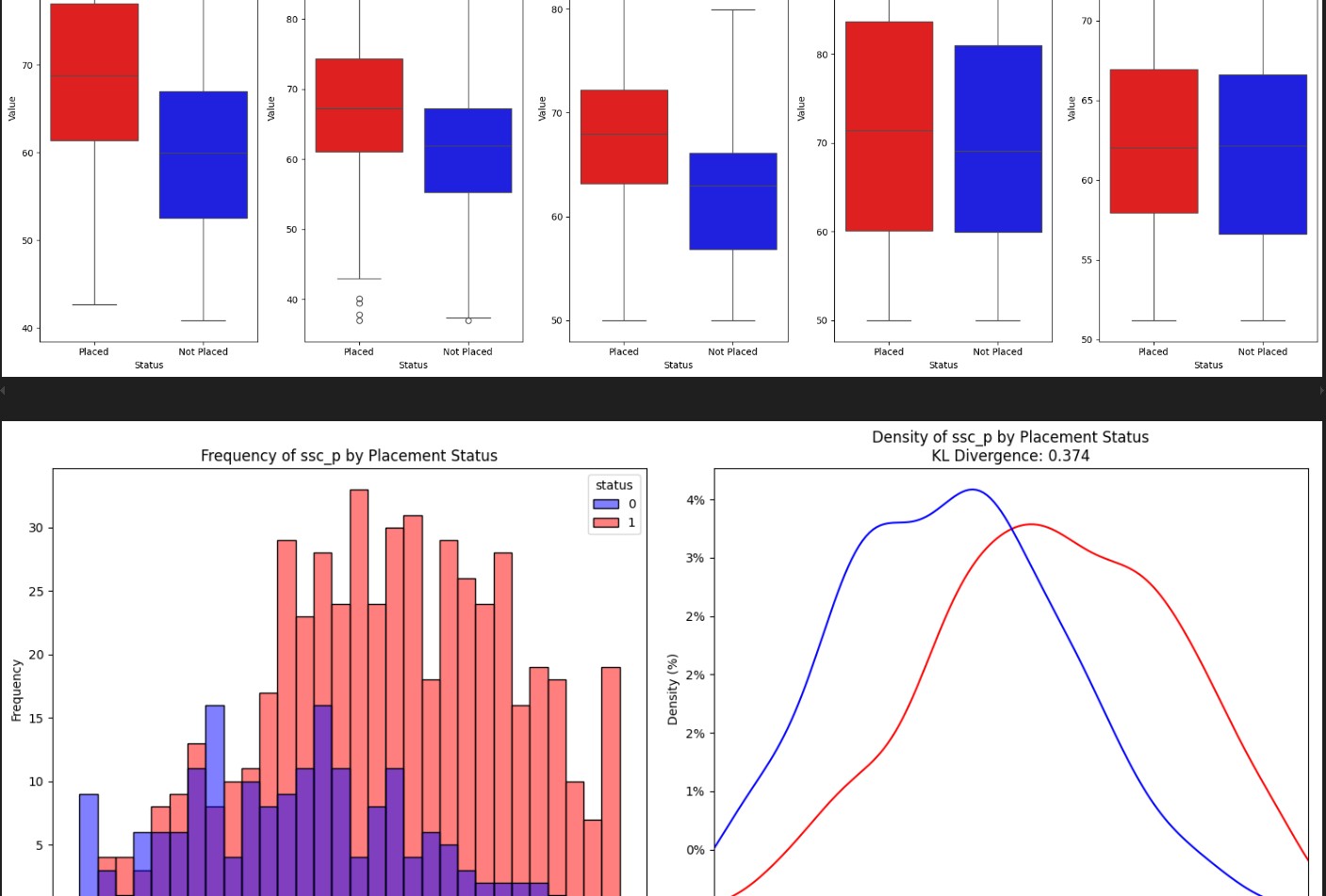
I was responsible for cleaning the dataset, performing exploratory data analysis, and building models to predict whether a student would be placed or not. This included handling missing values, encoding categorical features, and evaluating model performance using accuracy, precision, and recall metrics. I also visualized relationships between features such as education percentage, gender, specialization, and placement outcomes.
Development Process
We began with data exploration and visualization to understand feature distributions and correlations. I applied label encoding and addressed class imbalance using resampling techniques. Multiple machine learning models were trained and evaluated using cross-validation, with an optimized Random Forest model achieving the best balanced accuracy. Meanwhile, my teammate developed a regression model to predict expected salaries for placed students.
Challenges & Solutions
One major challenge was the imbalance between "placed" and "not placed" classes, which initially led to biased predictions. We attempted to mitigate this using stratified sampling and techniques like SMOTE, but the improvements were limited. Overfitting was another issue across most models, which we addressed using pruning and hyperparameter tuning — again, with only marginal improvements.
Outcome / Results
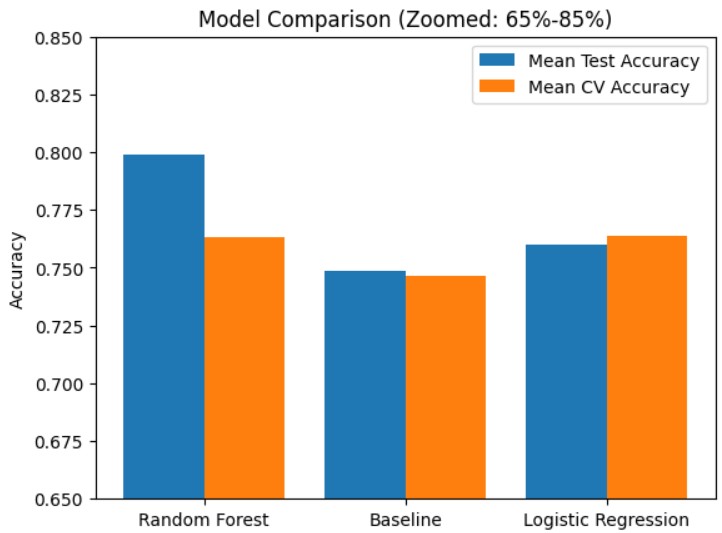
The final classification model achieved over 85% accuracy and provided clear insights into the factors most correlated with placement. Our visualizations revealed key patterns in student profiles, and the salary prediction model developed by my teammate showed how specialization and academic performance influenced expected compensation. These models form a solid foundation for tools that could support academic career guidance.
Reflection
This project deepened my understanding of working with real-world data, especially the importance of preprocessing and careful model evaluation. It highlighted the limitations of machine learning when faced with imbalanced datasets, and the need for critical thinking beyond just applying algorithms. Working alongside a teammate focused on regression also helped me appreciate the complementary nature of different machine learning tasks.